Note
Click here to download the full example code
Voice Activity Detection¶
Plot the VAD in signals and remove silences.
Currently soundpy has two base functions to complete voice-activity-detection.
1) soundpy.dsp.sound_index¶
This function is used in:
soundpy.feats.get_stft_clipped, soundpy.feats.get_samples_clipped,
and soundpy.feats.plot_vad
This form of VAD uses the energy in the signal to identify when sounds start and end, relative to the beginning and end of the entire sample. (It does not identify silences between sounds, as of yet.)
Strength¶
This is quite reliable across noise and speaker variety, especially when combined with the Wiener filter. It also catches a significant portion of the speech signal that is identified.
Weakness¶
This is less sensitive to certain speech sounds such as fricatives (s, f, h, etc.), causing it to miss speech activity consisting primarily of these sounds.
2) soundpy.dsp.vad¶
This function is used in:
soundpy.feats.get_vad_stft, soundpy.feats.get_vad_samples,
and soundpy.feats.plot_vad
This function (pulling from research) utilizes energy, frequency, and spectral flatness, which makes it less finicky when it comes to speech sounds (fricative vs plosive speech sounds). However, it is sometimes not sensitive enough to pick up general speech and when it does, it does not pick up as much of the entire speech signal.
Strength¶
This examines speech / sound activity throughout the signal, not just when it starts and ends. It is also more sensitive to a variety of speech sounds, not just those with high energy.
Weakness¶
With certain speakers / background sounds, the VAD is more or less sensitive, and difficult to predict.
Note¶
These may be used together and / or with a Wiener filter to balance out the strengths and weaknesses of each. One can also apply a extend_window_ms to broaden the VAD identified.
import os, sys
import inspect
currentdir = os.path.dirname(os.path.abspath(
inspect.getfile(inspect.currentframe())))
parentdir = os.path.dirname(currentdir)
parparentdir = os.path.dirname(parentdir)
packagedir = os.path.dirname(parparentdir)
sys.path.insert(0, packagedir)
import soundpy as sp
import numpy as np
import IPython.display as ipd
package_dir = '../../../'
os.chdir(package_dir)
sp_dir = package_dir
Load sample speech audio¶
We will look at how these two options handle two different speech samples. The speech samples will be combined but separated by a silence. They will also be altered with white noise.
“six”¶
This is a sample file from the speech commands dataset (Attribution 4.0 International (CC BY 4.0)) dataset: https://ai.googleblog.com/2017/08/launching-speech-commands-dataset.htmll license: https://creativecommons.org/licenses/by/4.0/
This is audio that has two fricatives in it: ‘s’ and ‘x’ which will show to cause issues as noise increases.
Combine the speech samples and add noise¶
Combine speech signals with silence between¶
This is to show the strengths and weaknesses of both VAD techniques.
p_silence = np.zeros(len(y_p))
y_p_long, snr_none = sp.dsp.add_backgroundsound(y_p, p_silence,
sr = sr,
snr = None,
pad_mainsound_sec = 1,
total_len_sec = 3,
random_seed = 40)
y_six_long, snr_none = sp.dsp.add_backgroundsound(y_six, p_silence,
sr = sr,
snr = None,
pad_mainsound_sec = 1,
total_len_sec = 3,
random_seed = 40)
y = np.concatenate((y_six_long, y_p_long))
sp.feats.plot(y, sr=sr, feature_type = 'signal', subprocess=True)
ipd.Audio(y, rate=sr)
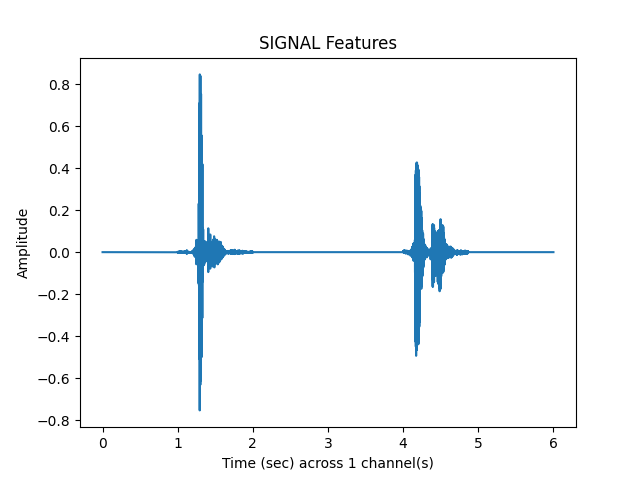
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:769: UserWarning:
Warning: `soundpy.dsp.clip_at_zero` found no samples close to zero. Clipping was not applied.
warnings.warn(msg)
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:531: UserWarning: The length of `audio_main` and `pad_mainsound_sec `exceeds `total_len_sec`. 1 samples from `audio_main` will be cut off in the `combined` audio signal.
warnings.warn('The length of `audio_main` and `pad_mainsound_sec `'+\
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Generate white noise¶
white_noise = sp.dsp.generate_noise(len(y), random_seed = 40)
Speech and Noise SNR 20¶
y_snr20, snr20 = sp.dsp.add_backgroundsound(
y, white_noise, sr=sr, snr = 20,random_seed = 40)
# round the measured snr:
snr20 = int(round(snr20))
snr20
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:769: UserWarning:
Warning: `soundpy.dsp.clip_at_zero` found no samples close to zero. Clipping was not applied.
warnings.warn(msg)
20
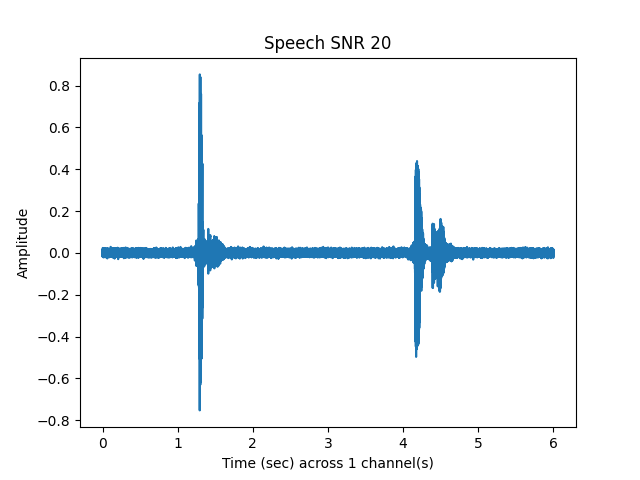
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Speech and Noise SNR 5¶
y_snr05, snr05 = sp.dsp.add_backgroundsound(
y, white_noise, sr=sr, snr = 5, random_seed = 40)
# round the measured snr:
snr05 = int(round(snr05))
snr05
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:769: UserWarning:
Warning: `soundpy.dsp.clip_at_zero` found no samples close to zero. Clipping was not applied.
warnings.warn(msg)
5
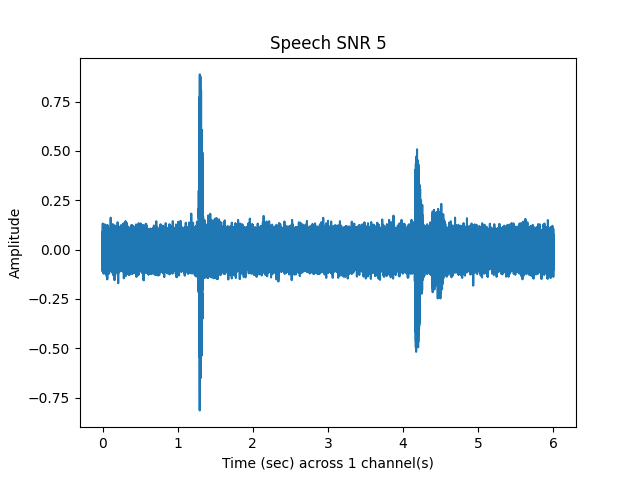
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Plot Voice Activity¶
NOTE: If no VAD, yellow dots are placed at the bottom. If VAD , yellow dots are placed at the top.
Set percent overlap¶
Percent overlap is how much each consecutive window (size win_size_ms) overlaps. These VAD functions can be reliably used at 0 and 0.5 percent_overlap. VAD does not need overlapping samples; however, better performance tends to occur with 0.5
percent_overlap = 0.5
Set background noise reference¶
For measuring background noise in signal, set amount
of beginning noise in milliseconds to use. Currently, this is
only relevant for soundpy.dsp.vad.
use_beg_ms = 120
VAD (SNR 20)¶
Option 1:¶
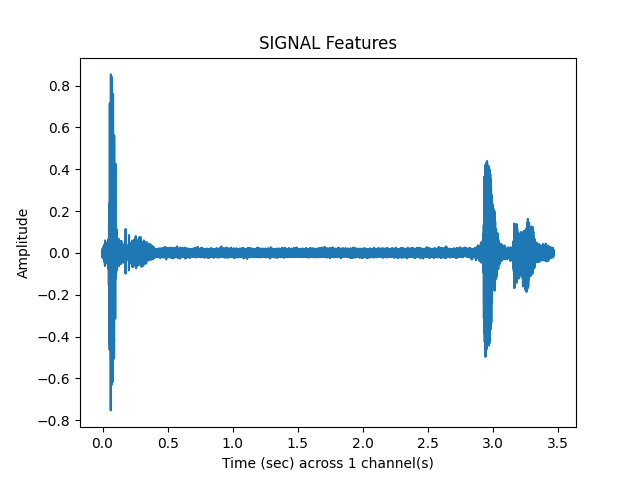
Cut off beginning and ending silences¶
sp.feats.plot_vad(y_snr20, sr=sr, beg_end_clipped = True,
percent_overlap = percent_overlap,
win_size_ms = win_size_ms)
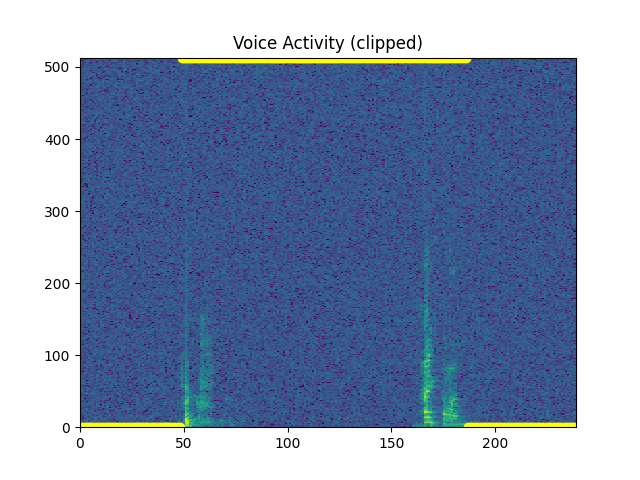
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:1756: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
plt.show()
clipped_samples, vad_matrix = sp.feats.get_samples_clipped(y_snr20, sr=sr, percent_overlap = percent_overlap,
win_size_ms = win_size_ms)
sp.feats.plot(clipped_samples, sr=sr, feature_type = 'signal', subprocess=True)
ipd.Audio(clipped_samples, rate= sr)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Option 2:¶
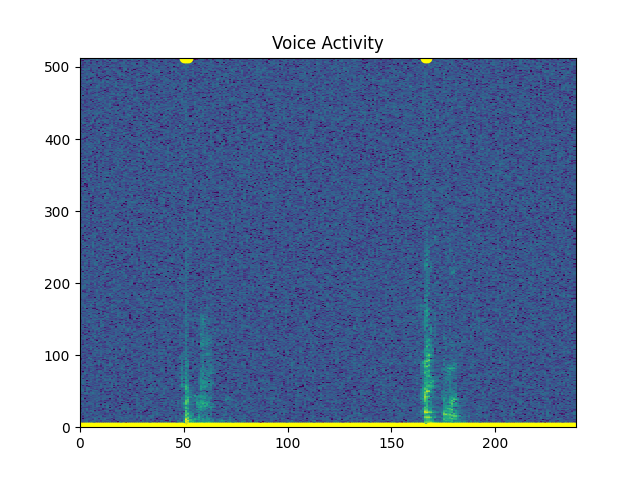
Check VAD through entire signal¶
sp.feats.plot_vad(y_snr20, sr=sr, beg_end_clipped = False,
percent_overlap = percent_overlap,
win_size_ms = win_size_ms)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:1756: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
plt.show()
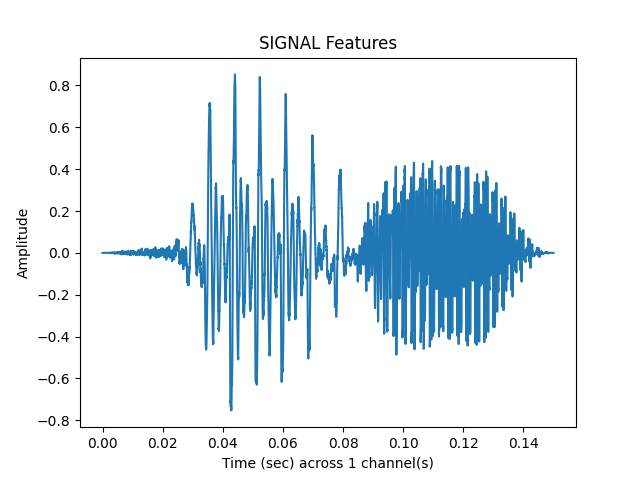
vad_samples, vad_matrix = sp.feats.get_vad_samples(
y_snr20, sr=sr, use_beg_ms = use_beg_ms,
percent_overlap = percent_overlap, win_size_ms = win_size_ms)
sp.feats.plot(vad_samples, sr=sr, feature_type = 'signal', subprocess=True)
ipd.Audio(vad_samples, rate = sr)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
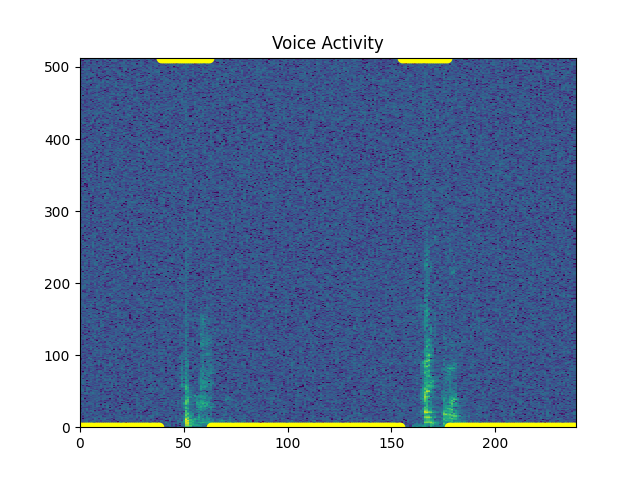
Let’s extend the window of VAD¶
sp.feats.plot_vad(y_snr20, sr=sr, beg_end_clipped = False,
extend_window_ms = 300, use_beg_ms = use_beg_ms,
percent_overlap = percent_overlap, win_size_ms = win_size_ms)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:1756: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
plt.show()
vad_samples, vad_matrix = sp.feats.get_vad_samples(
y_snr20, sr=sr, use_beg_ms = use_beg_ms, extend_window_ms = 300,
percent_overlap = percent_overlap, win_size_ms = win_size_ms)
sp.feats.plot(vad_samples, sr=sr, feature_type = 'signal', subprocess=True)
ipd.Audio(vad_samples, rate = sr)
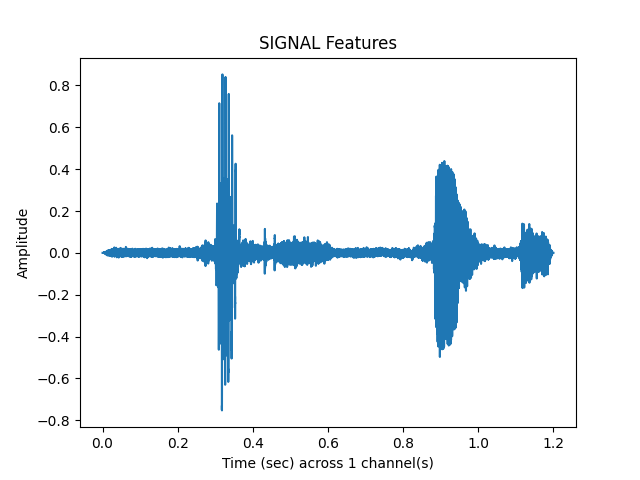
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
VAD (SNR 5)¶
Option 1:¶
Cut off beginning and ending silences¶
sp.feats.plot_vad(y_snr05, sr=sr, beg_end_clipped = True,
percent_overlap = percent_overlap,
win_size_ms = win_size_ms)
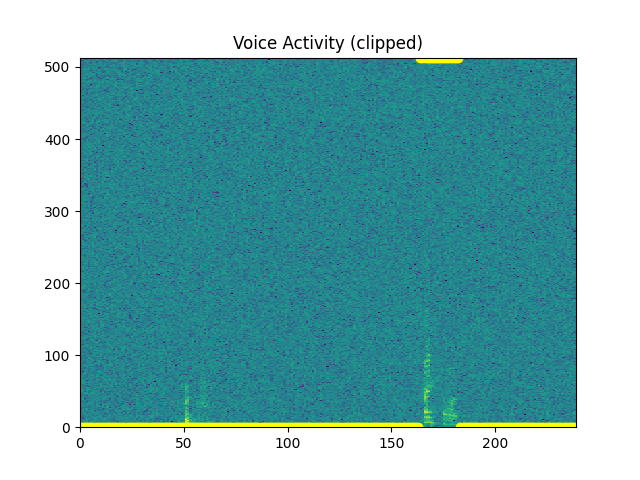
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:1756: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
plt.show()
clipped_samples, vad_matrix = sp.feats.get_samples_clipped(y_snr05, sr=sr, percent_overlap = percent_overlap,
win_size_ms = win_size_ms)
sp.feats.plot(clipped_samples, sr=sr, feature_type = 'signal', subprocess=True)
ipd.Audio(clipped_samples, rate= sr)
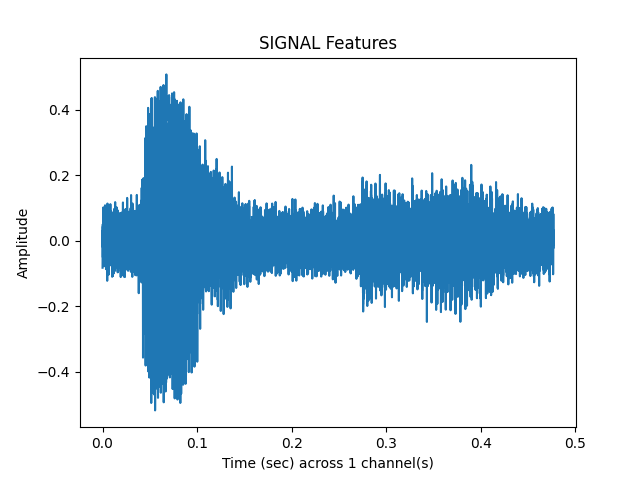
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Improves with Wiener filter and padding?¶
y_snr05_wf, sr = sp.filtersignal(
y_snr05, sr=sr, apply_postfilter = True)
sp.feats.plot_vad(y_snr05_wf, sr=sr, beg_end_clipped = True,
percent_overlap = percent_overlap,
win_size_ms = win_size_ms, extend_window_ms = 300)
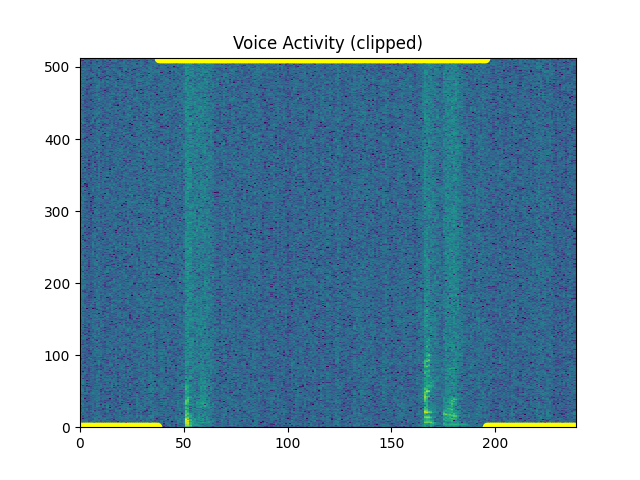
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:1756: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
plt.show()
clipped_samples, vad_matrix = sp.feats.get_samples_clipped(
y_snr05_wf, sr=sr, percent_overlap = percent_overlap,
win_size_ms = win_size_ms, extend_window_ms = 300)
sp.feats.plot(clipped_samples, sr=sr, feature_type = 'signal', subprocess=True)
ipd.Audio(clipped_samples, rate= sr)
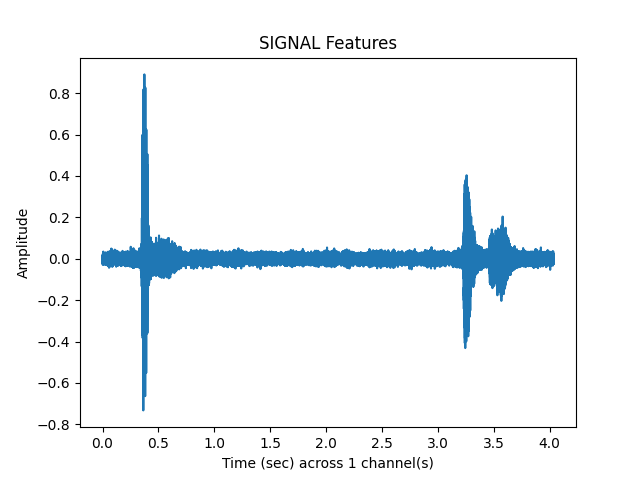
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Option 2:¶
Check VAD through entire signal¶
sp.feats.plot_vad(y_snr05, sr=sr, beg_end_clipped = False,
percent_overlap = percent_overlap, win_size_ms = win_size_ms)
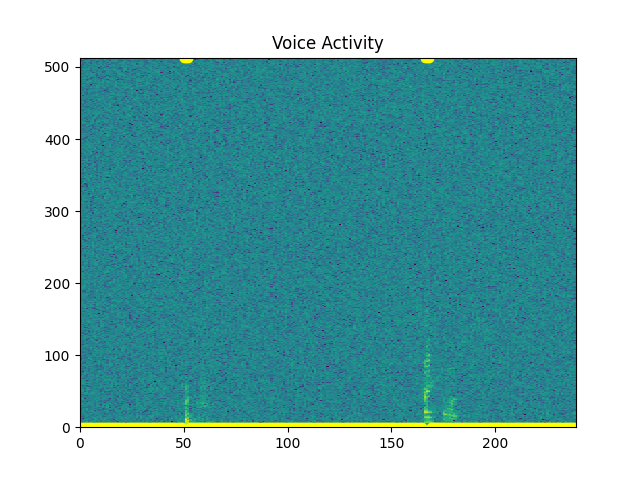
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:1756: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
plt.show()
vad_samples, vad_matrix = sp.feats.get_vad_samples(
y_snr05, sr=sr, use_beg_ms = use_beg_ms,
percent_overlap = percent_overlap, win_size_ms = win_size_ms)
sp.feats.plot(vad_samples, sr=sr, feature_type = 'signal', subprocess=True)
ipd.Audio(vad_samples, rate = sr)
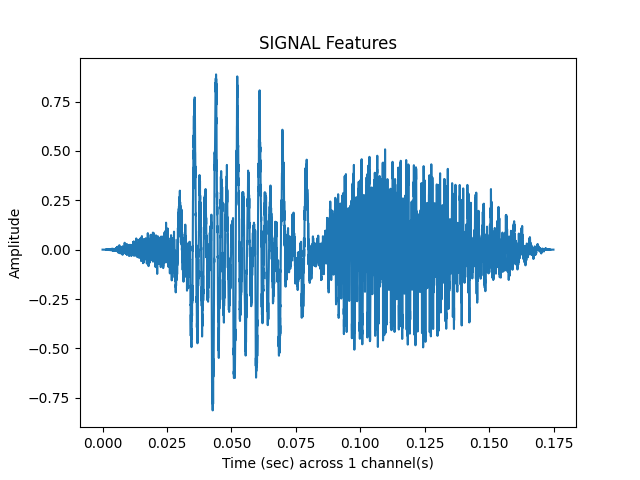
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Let’s extend the window of VAD¶
sp.feats.plot_vad(y_snr05, sr=sr, beg_end_clipped = False,
extend_window_ms = 300, use_beg_ms = use_beg_ms,
percent_overlap = percent_overlap, win_size_ms = win_size_ms)
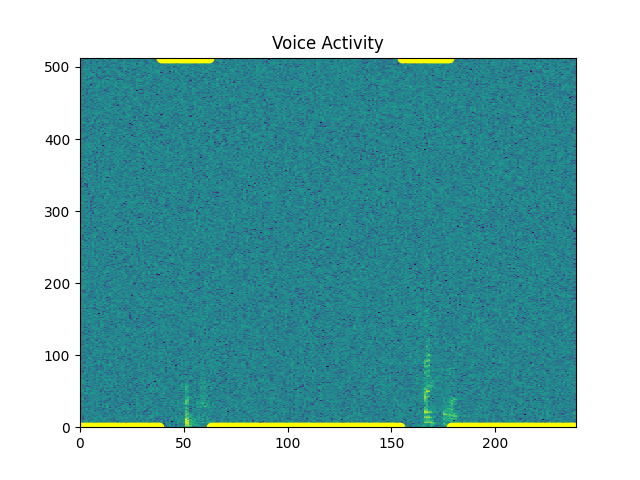
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:1756: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
plt.show()
vad_samples, vad_matrix = sp.feats.get_vad_samples(
y_snr05, sr=sr, use_beg_ms = use_beg_ms, extend_window_ms = 300,
percent_overlap = percent_overlap, win_size_ms = win_size_ms)
sp.feats.plot(vad_samples, sr=sr, feature_type = 'signal', subprocess=True)
ipd.Audio(vad_samples, rate = sr)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
In Sum¶
We can see from the above examples that the first option (clipping beginning and ending silences) works pretty well at higher SNRs and with filtering. It identified pretty well when the speech began and ended.
The second option (VAD throughout the signal) was perhaps better able to identify the existence of speech despite noise (without filtering); however, it only recognized a very small portion of it.
Despite these functions being a work in progress, I have found them to be quite useful when working with audio data for deep learning and other sound related projects.
Total running time of the script: ( 0 minutes 9.067 seconds)