Note
Click here to download the full example code
Augment Speech and Sound for Machine and Deep Learning¶
Augment audio to expanding datasets and train resilient models.
To see how SoundPy implements this, see the module soundpy.augment.
Note:¶
Consideration of what type of sound one is working with must be taken when performing augmentation. Not all speech and non-speech sounds should be handled the same. For example, you may want to augment speech differently if you are training a speech recognition model versus an emotion recognition model. Additionally, not all non-speech sounds behave the same, for example stationary (white noise) vs non-stationary (car horn) sounds.
In sum, awareness of how your sound data behave and what features of the sound are relevant for training models are important factors for sound data augmentation.
Below are a few augmentation techniques I have seen implemented in sound research; this is in no way a complete list of augmentation techniques.
import soundpy as sp
import IPython.display as ipd
Augmenting Speech¶
Designate the path relevant for accessing audiodata Note: the speech and sound come with the soundpy repo.
sp_dir = '../../../'
Speech sample:
speech = '{}audiodata/python.wav'.format(sp_dir)
speech = sp.utils.string2pathlib(speech)
Hear and see speech¶
sp.plotsound(f, sr=sr, feature_type='stft', title='Female Speech: "Python"', subprocess=True)
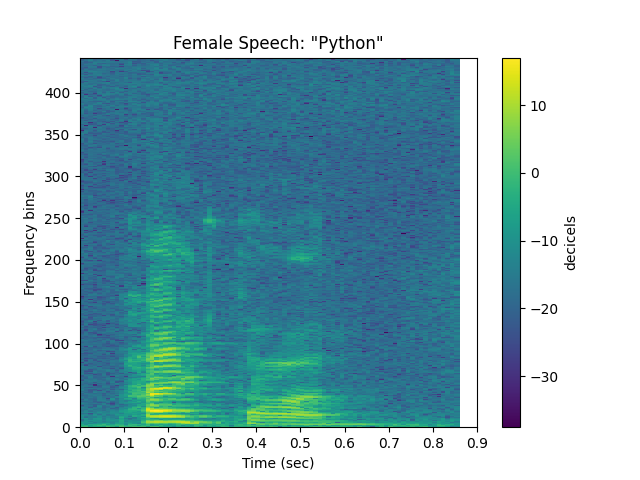
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Change Speed¶
Let’s increase the speed by 15%:
ipd.Audio(fast,rate=sr)
sp.plotsound(fast, sr = sr, feature_type = 'stft',
title = 'Female speech: 15% faster',
subprocess=True)
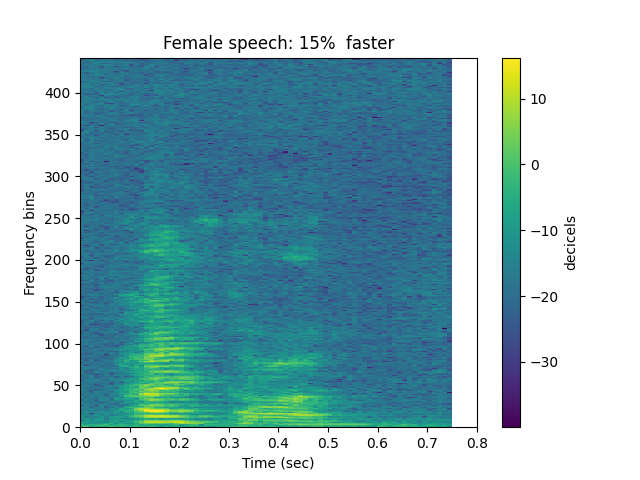
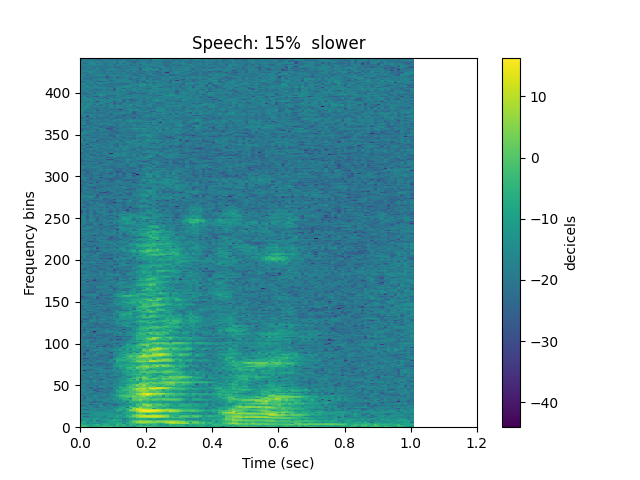
Let’s decrease the speed by 15%:
ipd.Audio(slow, rate = sr)
sp.plotsound(slow, sr = sr, feature_type = 'stft',
title = 'Speech: 15% slower', subprocess=True)
Add Noise¶
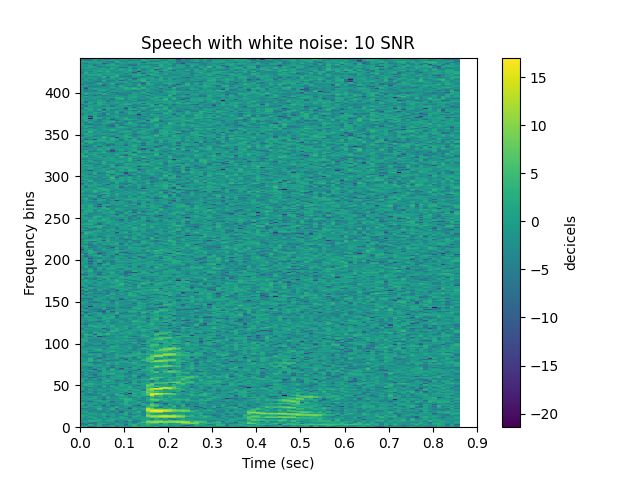
Add white noise: 10 SNR
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:769: UserWarning:
Warning: `soundpy.dsp.clip_at_zero` found no samples close to zero. Clipping was not applied.
warnings.warn(msg)
ipd.Audio(noisy,rate=sr)
sp.plotsound(noisy, sr=sr, feature_type='stft',
title='Speech with white noise: 10 SNR', subprocess=True)
Harmonic Distortion¶
ipd.Audio(hd,rate=sr)
sp.plotsound(hd, sr=sr, feature_type='stft',
title='Speech with harmonic distortion', subprocess=True)
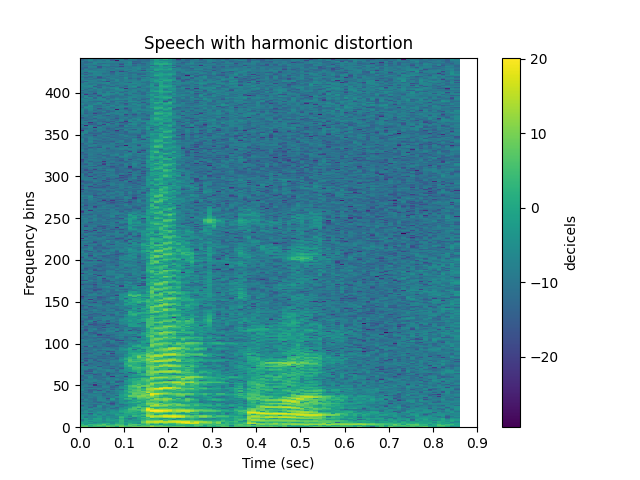
Pitch Shift¶
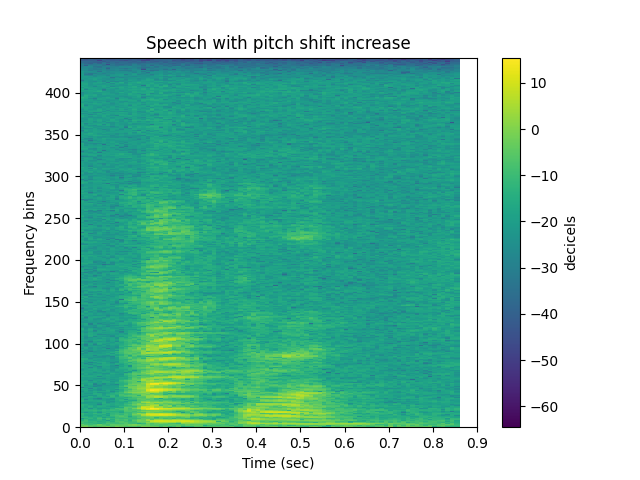
Pitch shift increase
ipd.Audio(psi,rate=sr)
sp.plotsound(psi, sr=sr, feature_type='stft',
title='Speech with pitch shift increase', subprocess=True)
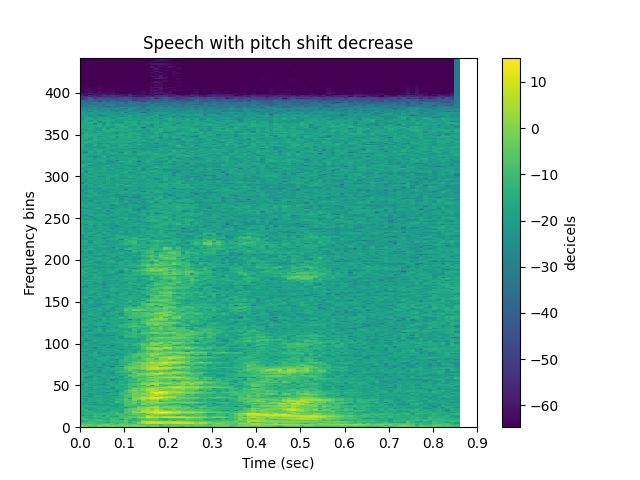
Pitch shift decrease
ipd.Audio(psd,rate=sr)
sp.plotsound(psd, sr=sr, feature_type='stft',
title='Speech with pitch shift decrease', subprocess=True)
- Vocal Tract Length Perturbation
Note: this is still experimental.
In order to listen to this, we need to turn the stft into samples:
sp.feats.plot(vtlp_stft, sr=sr, feature_type='stft',
title='VTLP (factor {})'.format(a), subprocess=True)
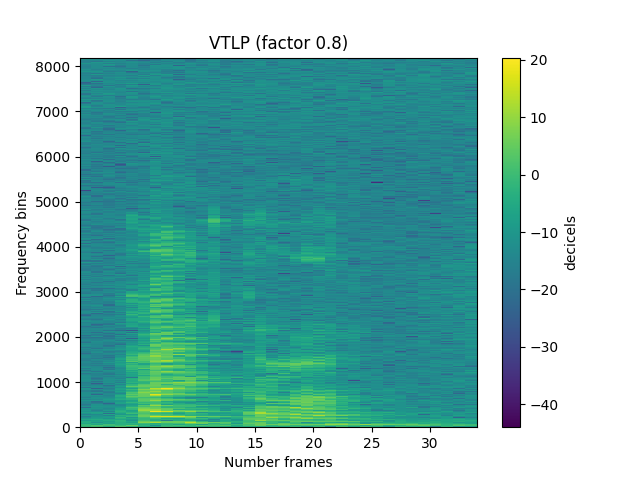
Vocal tract length perturbation (by factor 0.8 to 1.2)
In order to listen to this, we need to turn the stft into samples:
sp.feats.plot(vtlp_stft, sr=sr, feature_type='stft',
title='VTLP (factor {})'.format(a), subprocess=True)
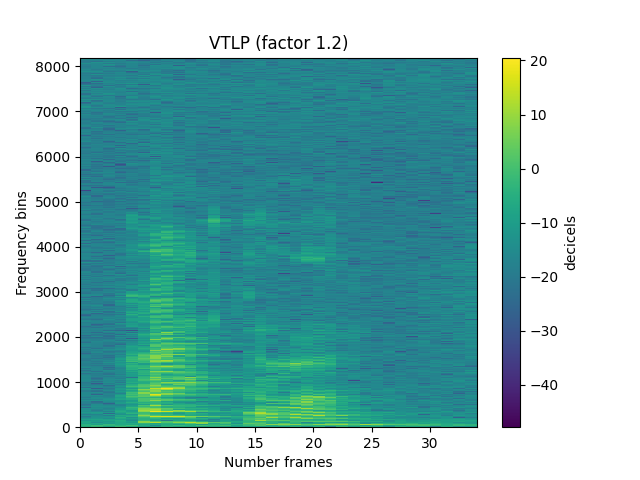
Augmenting non-speech signals¶
# Car horn sample:
honk = '{}audiodata/car_horn.wav'.format(sp_dir)
honk = sp.utils.string2pathlib(honk)
Hear and see sound signal¶
sp.plotsound(h, sr=sr, feature_type='stft',
title='Car Horn', subprocess=True)
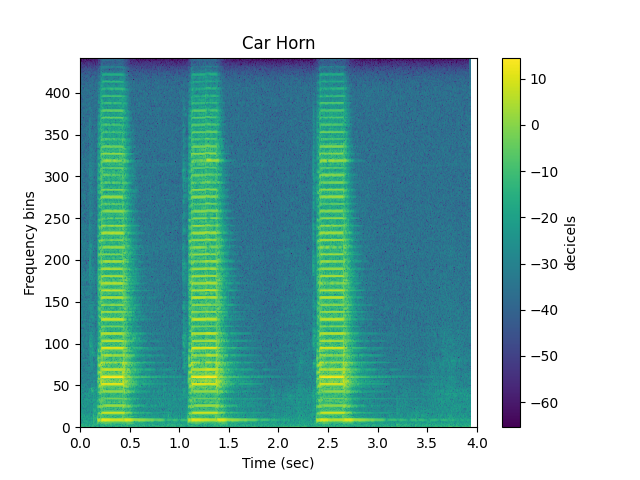
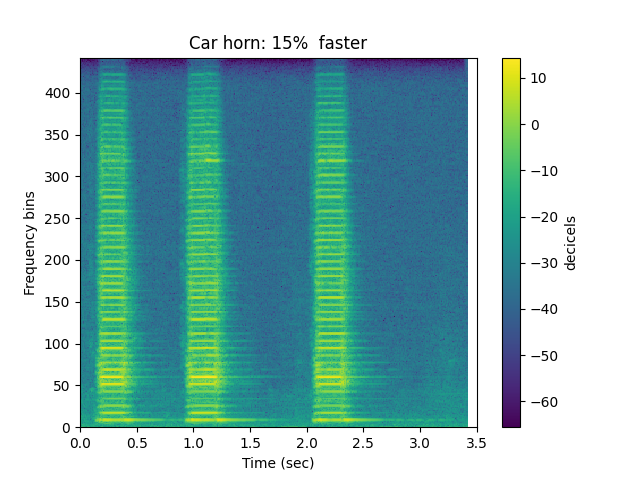
Change Speed¶
Let’s increase the speed by 15%:
ipd.Audio(fast,rate=sr)
sp.plotsound(fast, sr=sr, feature_type='stft',
title='Car horn: 15% faster', subprocess=True)
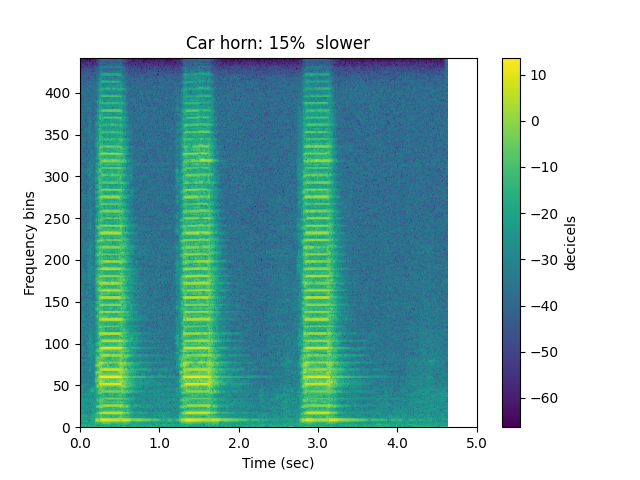
Let’s decrease the speed by 15%:
ipd.Audio(slow,rate=sr)
sp.plotsound(slow, sr=sr, feature_type='stft',
title='Car horn: 15% slower', subprocess=True)
Add Noise¶
Add white noise
ipd.Audio(h_noisy,rate=sr)
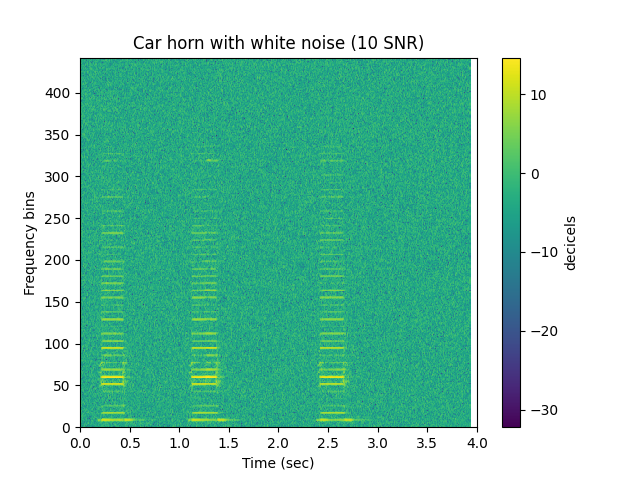
sp.plotsound(h_noisy, sr=sr, feature_type='stft',
title='Car horn with white noise (10 SNR)',
subprocess=True)
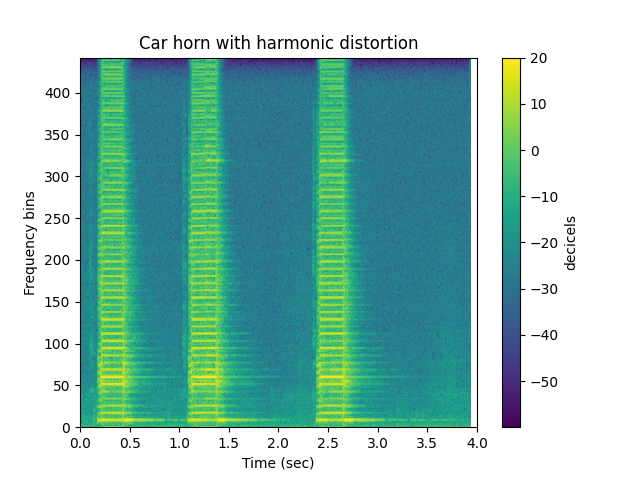
Harmonic Distortion¶
ipd.Audio(hd,rate=sr)
sp.plotsound(hd, sr=sr, feature_type='stft',
title='Car horn with harmonic distortion',
subprocess=True)
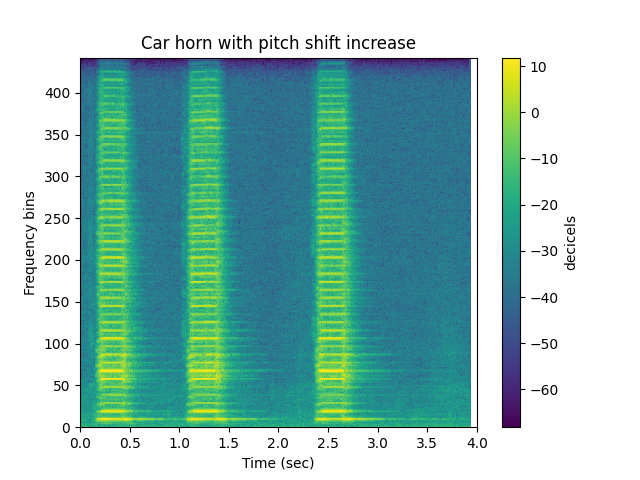
Pitch Shift¶
Pitch shift increase
ipd.Audio(psi,rate=sr)
sp.plotsound(psi, sr=sr, feature_type='stft',
title='Car horn with pitch shift increase',
subprocess=True)
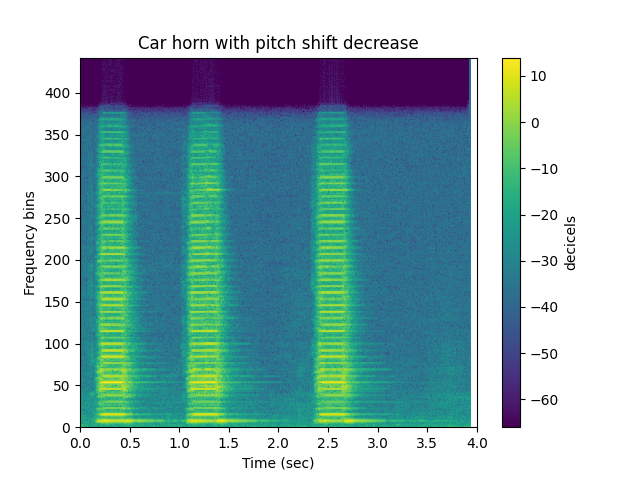
Pitch shift decrease
ipd.Audio(psd,rate=sr)
sp.plotsound(psd, sr=sr, feature_type='stft',
title='Car horn with pitch shift decrease',
subprocess=True)
Time Shift¶
We’ll apply a random shift to the sound
ipd.Audio(h_shift,rate=sr)
sp.plotsound(h_shift, sr=sr, feature_type='stft',
title='Car horn: time shifted',
subprocess=True)
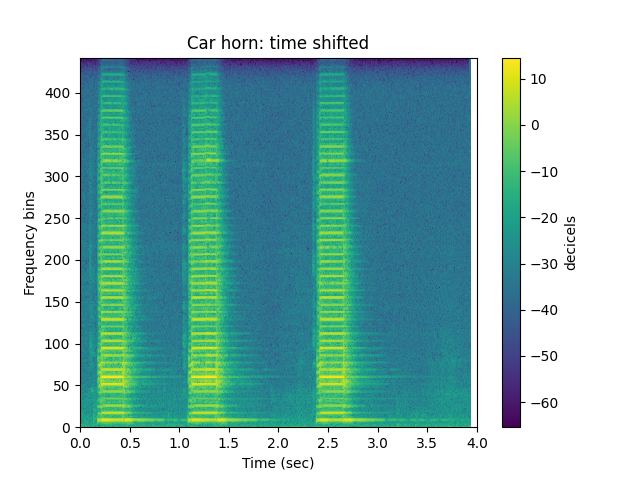
Shuffle the Sound¶
ipd.Audio(h_shuffle,rate=sr)
sp.plotsound(h_shuffle, sr=sr, feature_type='stft',
title='Car horn: shuffled', subprocess=True)
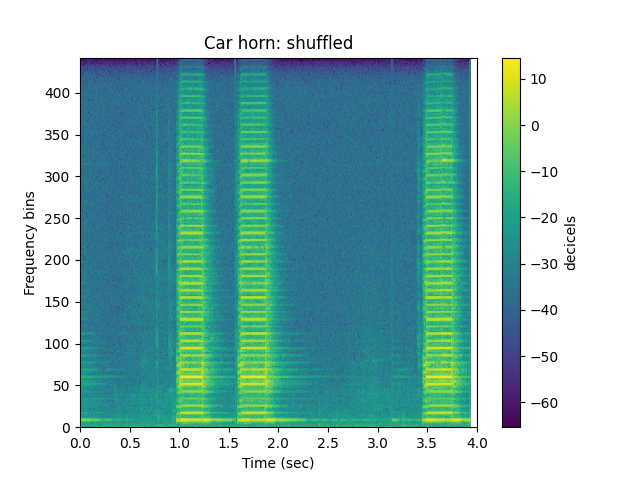
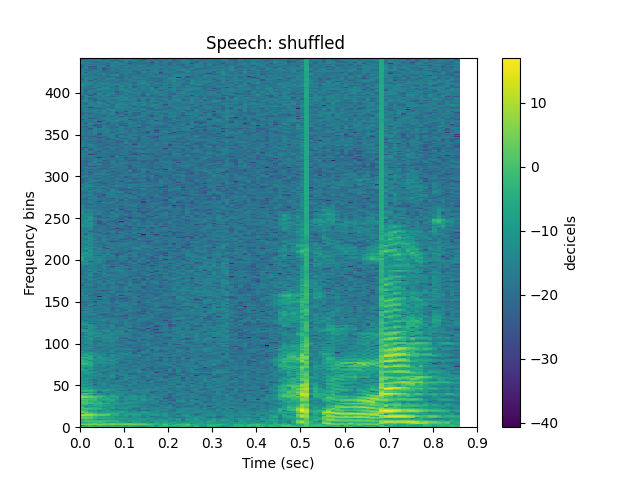
Just for kicks let’s do the same to speech and see how that influences the signal:
ipd.Audio(h_shuffle,rate=sr)
sp.plotsound(h_shuffle, sr=sr, feature_type='stft',
title='Speech: shuffled ', subprocess=True)
Total running time of the script: ( 0 minutes 10.779 seconds)