Note
Click here to download the full example code
Implement a Denoising Autoencoder¶
Implement denoising autoencoder to denoise a noisy speech signal.
To see how soundpy implements this, see soundpy.models.builtin.denoiser_run.
Let’s import soundpy and other packages
import soundpy as sp
import numpy as np
# for playing audio in this notebook:
import IPython.display as ipd
As well as the deep learning component of soundpy
from soundpy import models as spdl
Prepare for Implementation: Data Organization¶
Set path relevant for audio data for this example
sp_dir = '../../../'
Set model pathway¶
Currently, this expects a model saved with weights, with a .h5 extension. (See model below)
The soundpy repo offers a pre-trained denoiser, which we’ll use.
model = '{}audiodata/models/'.format(sp_dir)+\
'denoiser/example_denoiser_stft.h5'
# ensure is a pathlib.PosixPath object
print(model)
model = sp.utils.string2pathlib(model)
model_dir = model.parent
Out:
../../../audiodata/models/denoiser/example_denoiser_stft.h5
What is in this folder?
files = list(model_dir.glob('*.*'))
for f in files:
print(f.name)
Out:
example_denoiser_stft.h5
log_extraction_settings.csv
log.csv
Provide dictionary with feature extraction settings¶
If soundpy extracts features for you, a ‘log_extraction_settings.csv’
file will be saved, which includes relevant feature settings for implementing
the model; see soundpy.feats.save_features_datasets
feat_settings = sp.utils.load_dict(
model_dir.joinpath('log_extraction_settings.csv'))
for key, value in feat_settings.items():
print(key, ' --> ', value)
# change objects that were string to original format
import ast
try:
feat_settings[key] = ast.literal_eval(value)
except ValueError:
pass
except SyntaxError:
pass
Out:
dur_sec --> 3
feature_type --> stft noisy
feat_type --> stft
complex_vals --> True
sr --> 22050
num_feats --> 177
n_fft --> 352
win_size_ms --> 16
frame_length --> 352
percent_overlap --> 0.5
window --> hann
frames_per_sample --> 11
labeled_data --> False
visualize --> True
input_shape --> (35, 11, 177)
desired_shape --> (385, 177)
use_librosa --> True
center --> True
mode --> reflect
subsection_data --> True
divide_factor --> 10
For the purposes of plotting, let’s use some of the settings defined:
feature_type = feat_settings['feature_type']
sr = feat_settings['sr']
Provide new audio for the denoiser to denoise!¶
We’ll use sample speech from the soundpy repo:
speech = sp.string2pathlib('{}audiodata/python.wav'.format(sp_dir))
s, sr = sp.loadsound(speech, sr=sr)
Let’s add some white noise (10 SNR)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:1027: UserWarning:
Warning: voice-activity-detection works best with sample rates above 44100 Hz. Current `sr` set at 22050.
warnings.warn(msg)
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:2782: UserWarning:
Warning: VAD works best with sample rates above 44100 Hz.
warnings.warn(msg)
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:769: UserWarning:
Warning: `soundpy.dsp.clip_at_zero` found no samples close to zero. Clipping was not applied.
warnings.warn(msg)
What does the noisy audio look like?¶
sp.plotsound(s_n, sr = sr, feature_type='signal', subprocess=True)
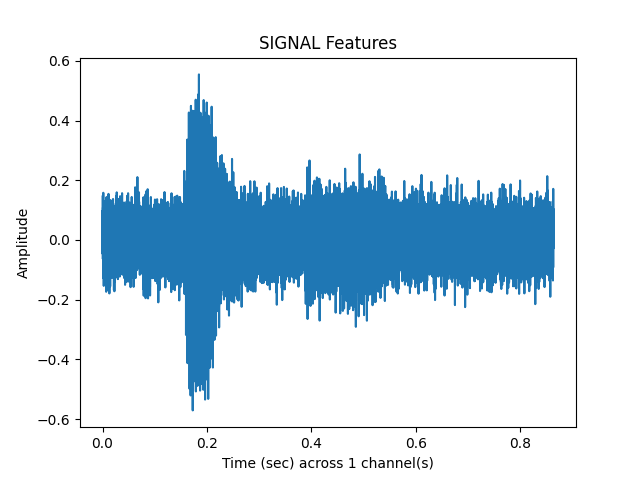
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
What does the clean audio look like?¶
sp.plotsound(s, sr = sr, feature_type='signal', subprocess=True)
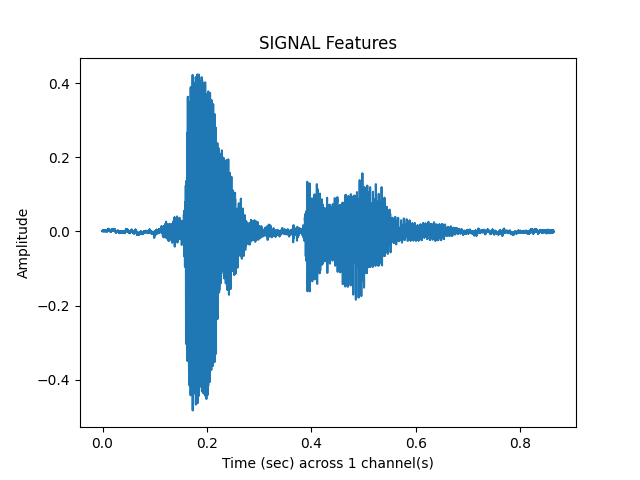
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Built-In Denoiser Functionality¶
We just need to feed the model path, the noisy sample path, and the feature settings dictionary we looked at above.
Out:
WARNING:tensorflow:Model was constructed with shape (None, 11, 177, 1) for input Tensor("conv2d_1_input:0", shape=(None, 11, 177, 1), dtype=float32), but it was called on an input with incompatible shape (None, 35, 11, 177).
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/models/builtin.py:758: UserWarning:
WARNING: adjustments to feature extraction in a more recent SoundPy version may result in imperfect feature alignmnet with a model trained with features generated with a previous SoundPy version. Sincerest apologies!
warnings.warn(msg)
How does is the output look?¶
sp.plotsound(y, sr=sr, feature_type = feature_type, subprocess=True)
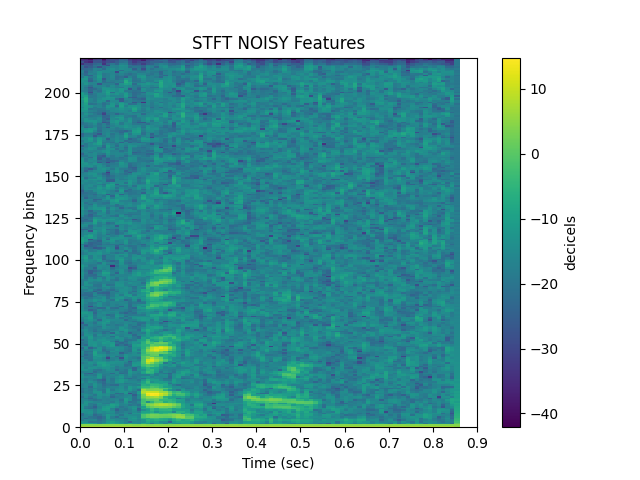
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
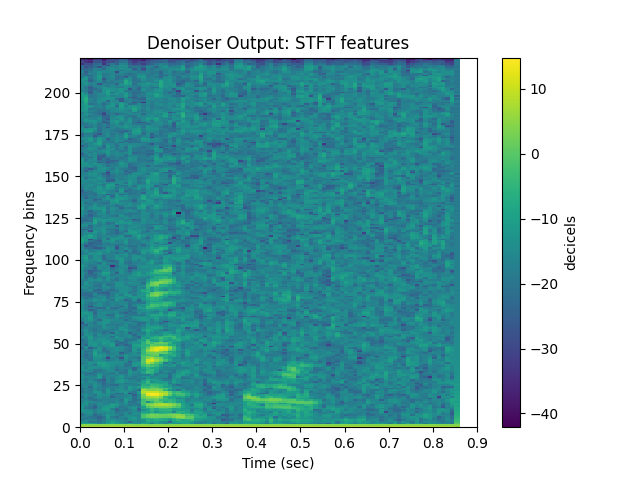
How do the features compare?¶
STFT features of the noisy input speech:
sp.plotsound(s_n, sr=sr, feature_type = 'stft', energy_scale = 'power_to_db',
title = 'Noisy input: STFT features', subprocess=True)
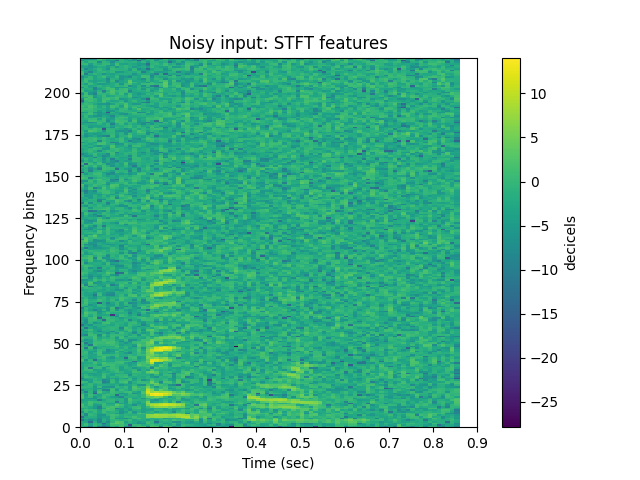
STFT features of the output
sp.plotsound(y, sr=sr, feature_type = 'stft', energy_scale = 'power_to_db',
title = 'Denoiser Output: STFT features', subprocess=True)
STFT features of the clean version of the audio:
sp.plotsound(s, sr=sr, feature_type = 'stft', energy_scale = 'power_to_db',
title = 'Clean "target" audio: STFT features', subprocess=True)
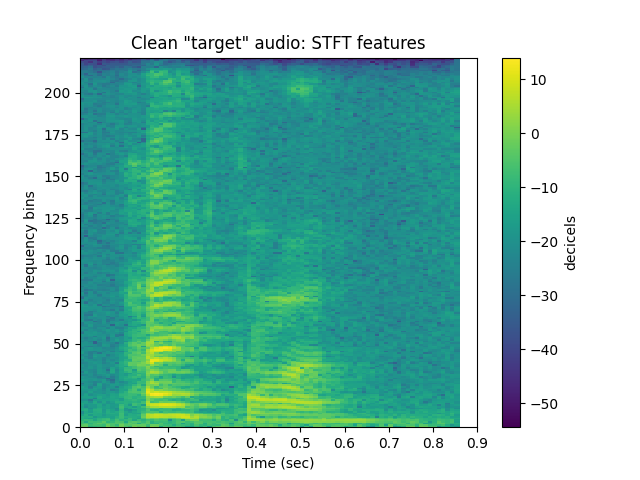
It’s not perfect but for a pretty simple implementation, the noise is gone and you can hear the person speaking. Pretty cool!
Total running time of the script: ( 0 minutes 5.950 seconds)