Note
Click here to download the full example code
Add Noise to Speech at Specific SNR Levels¶
Add noise to speech at specific signal-to-noise ratio levels.
To see how soundpy implements this, see soundpy.dsp.add_backgroundsound.
Let’s import soundpy, and ipd for playing audio data
import soundpy as sp
import IPython.display as ipd
Define the speech and noise data samples¶
I will use speech and noise data from the soundpy repo.
Designate path relevant for accessing audiodata
sp_dir = '../../../'
Speech sample:
speech_sample = '{}audiodata/python.wav'.format(sp_dir)
speech_sample = sp.utils.string2pathlib(speech_sample)
# as pathlib object, can do the following:
word = speech_sample.stem
word
Out:
'python'
Noise sample:
noise_sample = '{}audiodata/background_samples/cafe.wav'.format(sp_dir)
noise_sample = sp.utils.string2pathlib(noise_sample)
# as pathlib object, can do the following:
noise = noise_sample.stem
noise
Out:
'cafe'
Hear Clean Speech¶
I’m using a higher sample rate here as calculating SNR performs best upwards of 44100 Hz.
Hear Signal-to-Noise Ratio 20¶
noisyspeech_20snr, snr20 = sp.dsp.add_backgroundsound(
speech_sample,
noise_sample,
sr = sr,
snr = 20)
ipd.Audio(noisyspeech_20snr,rate=sr)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:769: UserWarning:
Warning: `soundpy.dsp.clip_at_zero` found no samples close to zero. Clipping was not applied.
warnings.warn(msg)
snr20 is simply the measured SNR post adjustment fo the noise signal. This is useful to check that the indicated snr is at least close to the resulting snr.
snr20
Out:
19.999968503067556
Hear Signal-to-Noise Ratio 5¶
noisyspeech_5snr, snr5 = sp.dsp.add_backgroundsound(
speech_sample,
noise_sample,
sr = sr,
snr = 5)
ipd.Audio(noisyspeech_5snr,rate=sr)
snr5
Out:
5.000011686690687
Visualize the Audio Samples¶
See Clean Speech (raw signal)¶
sp.plotsound(speech_sample, feature_type='signal',
sr = sr, title = 'Speech: ' + word.upper(),
subprocess=True)
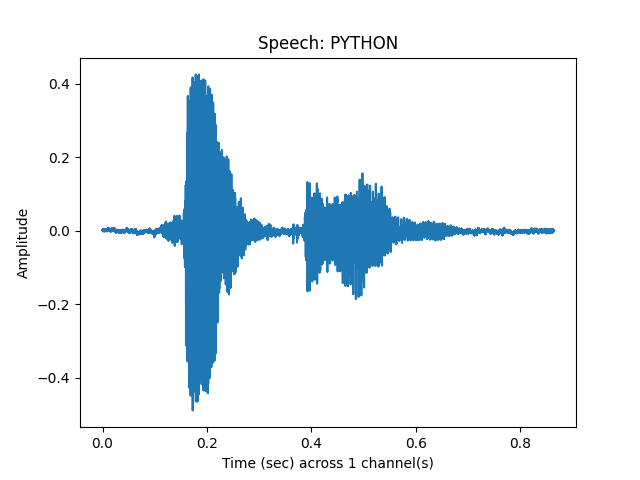
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
See Clean Speech (stft)¶
sp.plotsound(speech_sample, feature_type='stft',
sr = sr, title = 'Speech: ' + word.upper(),
subprocess=True)
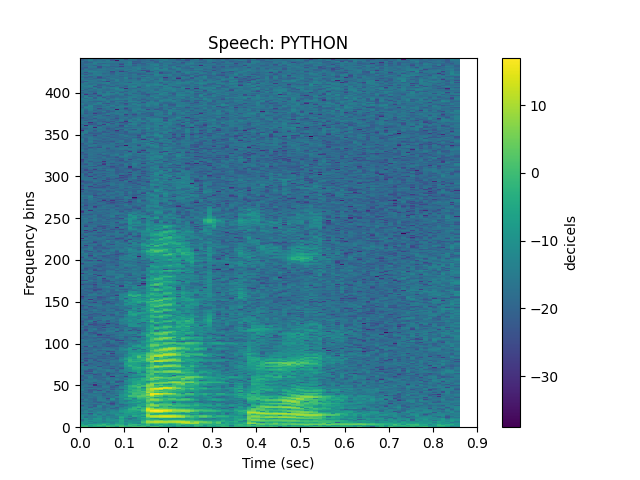
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
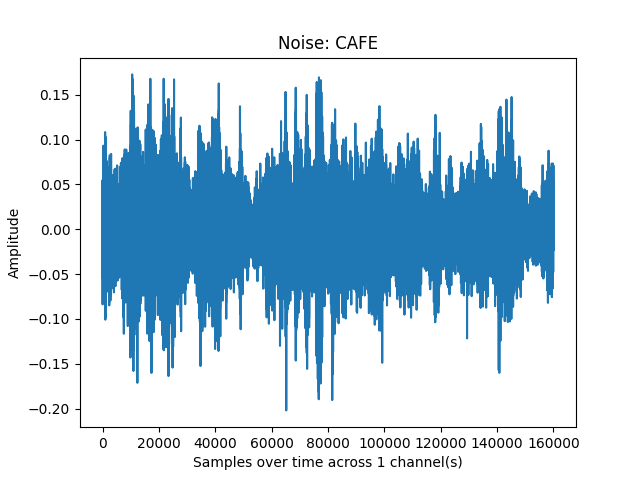
sp.plotsound(noise_sample, feature_type='signal',
title = 'Noise: ' + noise.upper(), subprocess=True)
sp.plotsound(noise_sample, feature_type='stft',
title = 'Noise: ' + noise.upper(), subprocess=True)
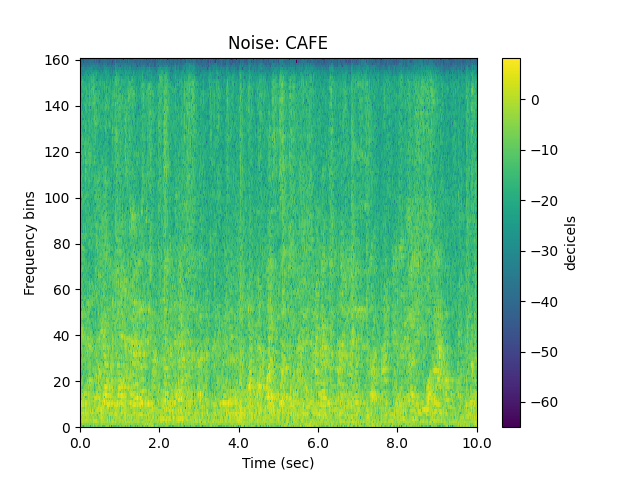
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
See Noisy Speech: SNR 20 (raw signal)¶
sp.plotsound(noisyspeech_20snr, sr = sr, feature_type = 'signal',
title = '"{}" with {} noise at SNR 20'.format(word.upper(), noise.upper()),
subprocess=True)
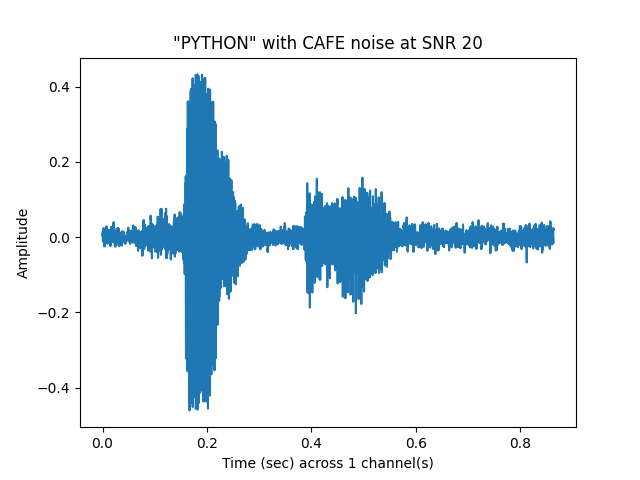
See Noisy Speech: SNR 20 (stft)¶
sp.plotsound(noisyspeech_20snr, sr = sr, feature_type = 'stft',
title = '"{}" with {} noise at SNR 20'.format(word.upper(), noise.upper()),
subprocess=True)
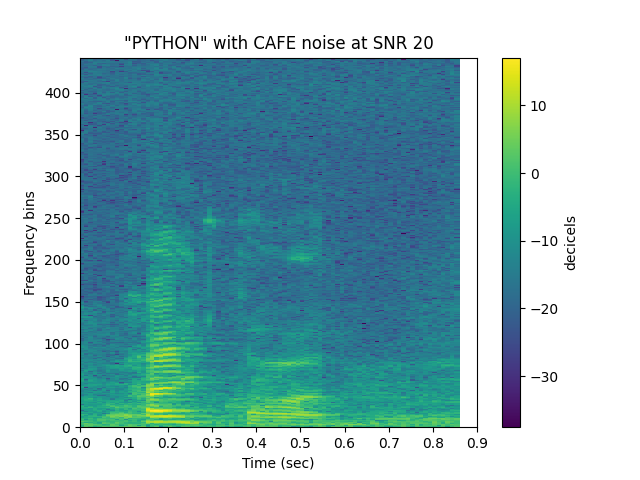
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
See Noisy Speech: SNR 5 (raw signal)¶
sp.plotsound(noisyspeech_5snr, sr = sr, feature_type = 'signal',
title = '"{}" with {} noise at SNR 5'.format(word.upper(), noise.upper()),
subprocess=True)
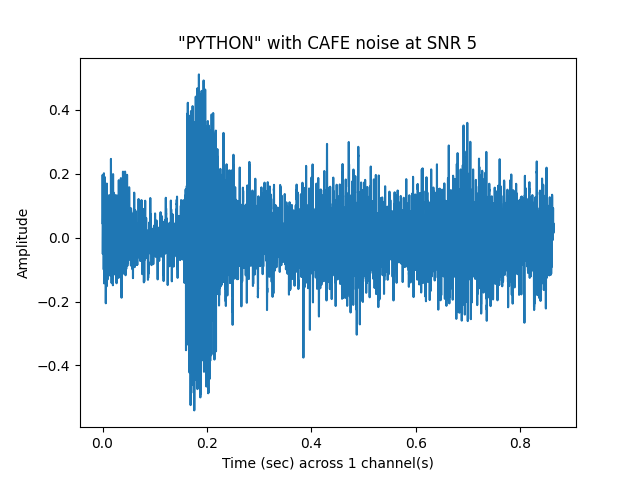
See Noisy Speech: SNR 5 (stft)¶
sp.plotsound(noisyspeech_20snr, sr = sr, feature_type = 'stft',
title = '"{}" with {} noise at SNR 5'.format(word.upper(), noise.upper()),
subprocess=True)
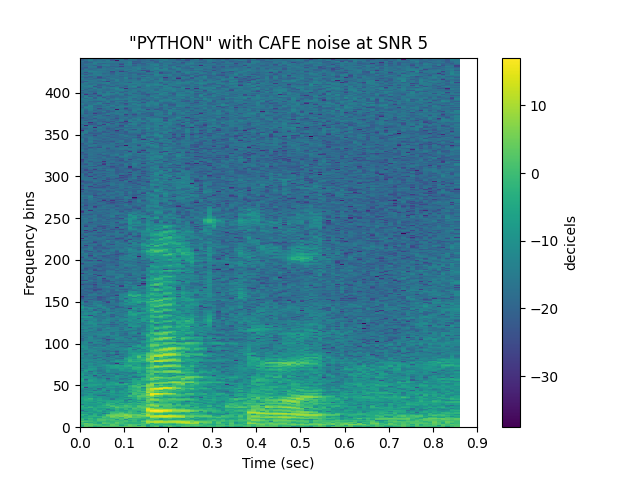
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Make Combined Sound Longer¶
Pad Speech and Set Total Length¶
noisyspeech_20snr, snr20 = sp.dsp.add_backgroundsound(
speech_sample,
noise_sample,
sr = sr,
snr = 20,
pad_mainsound_sec = 1,
total_len_sec = 4)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:769: UserWarning:
Warning: `soundpy.dsp.clip_at_zero` found no samples close to zero. Clipping was not applied.
warnings.warn(msg)
ipd.Audio(noisyspeech_20snr,rate=sr)
sp.plotsound(noisyspeech_20snr, sr = sr, feature_type = 'signal',
title = '"{}" with {} noise at SNR 20'.format(word.upper(), noise.upper()),
subprocess=True)
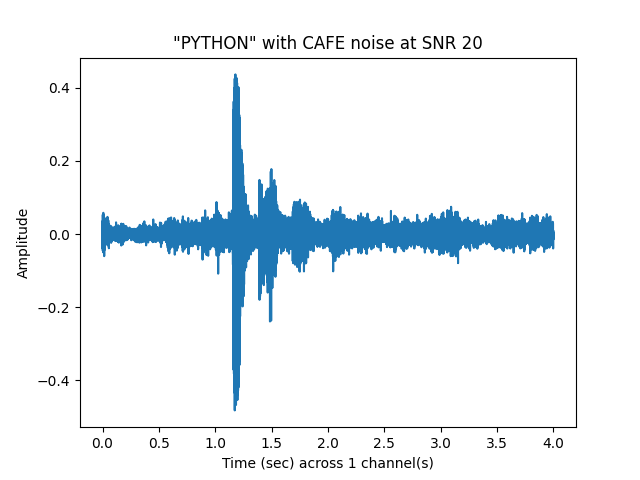
Make Combined Sound Shorter¶
Set Total Length¶
noisyspeech_20snr, snr20 = sp.dsp.add_backgroundsound(
speech_sample,
noise_sample,
sr = sr,
snr = 20,
total_len_sec = 0.75)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:531: UserWarning: The length of `audio_main` and `pad_mainsound_sec `exceeds `total_len_sec`. 5018 samples from `audio_main` will be cut off in the `combined` audio signal.
warnings.warn('The length of `audio_main` and `pad_mainsound_sec `'+\
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:769: UserWarning:
Warning: `soundpy.dsp.clip_at_zero` found no samples close to zero. Clipping was not applied.
warnings.warn(msg)
ipd.Audio(noisyspeech_20snr,rate=sr)
sp.plotsound(noisyspeech_20snr, sr = sr, feature_type = 'signal',
title = '"{}" with {} noise at SNR 20'.format(word.upper(), noise.upper()),
subprocess=True)
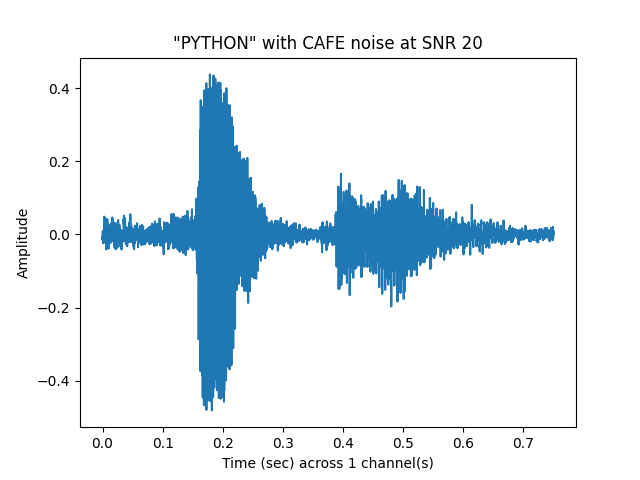
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Wrap the Background Sound¶
noisyspeech_20snr, snr20 = sp.dsp.add_backgroundsound(
speech_sample,
noise_sample,
sr = sr,
snr = 20,
wrap = True,
pad_mainsound_sec = 2,
total_len_sec = 5)
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/dsp.py:769: UserWarning:
Warning: `soundpy.dsp.clip_at_zero` found no samples close to zero. Clipping was not applied.
warnings.warn(msg)
ipd.Audio(noisyspeech_20snr,rate=sr)
sp.plotsound(noisyspeech_20snr, sr = sr, feature_type = 'signal',
title = '"{}" with {} noise at SNR 20'.format(word.upper(), noise.upper()),
subprocess=True)
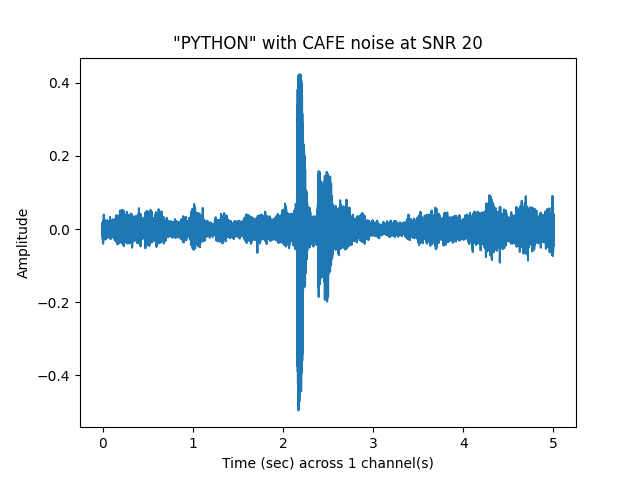
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/feats.py:117: UserWarning: Due to matplotlib using AGG backend, cannot display plot. Therefore, the plot will be saved here: current working directory
warnings.warn(msg)
Total running time of the script: ( 0 minutes 5.720 seconds)