Note
Click here to download the full example code
Audio Dataset Exploration and Formatting¶
Examine audio files within a dataset, and reformat them if desired.
To see how soundpy implements this, see soundpy.builtin.dataset_logger and
soundpy.builtin.dataset_formatter.
Let’s import soundpy
import soundpy as sp
Dataset Exploration¶
Designate path relevant for accessing audiodata
sp_dir = '../../../'
I will explore files in a small dataset on my computer with varying file formats.
dataset_path = '{}audiodata2/'.format(sp_dir)
dataset_info_dict = sp.builtin.dataset_logger('{}audiodata2/'.format(sp_dir));
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/files.py:352: UserWarning: Some files did not match those acceptable by this program. (i.e. non-audio files) The number of files not included: 3300
warnings.warn(message)
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/files.py:105: UserWarning:
WARNING: Most functionality has not been tested with stereo sound. Many functions may fail or not work as expected. Apologies for the inconvenience!
warnings.warn(msg)
3% through logging audio file details
6% through logging audio file details
9% through logging audio file details
12% through logging audio file details
16% through logging audio file details
19% through logging audio file details
22% through logging audio file details
25% through logging audio file details
29% through logging audio file details
32% through logging audio file details
35% through logging audio file details
38% through logging audio file details
41% through logging audio file details/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/p3_test/lib/python3.8/site-packages/librosa/core/audio.py:162: UserWarning: PySoundFile failed. Trying audioread instead.
warnings.warn("PySoundFile failed. Trying audioread instead.")
45% through logging audio file details
48% through logging audio file details
51% through logging audio file details
54% through logging audio file details
58% through logging audio file details
61% through logging audio file details
64% through logging audio file details/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/p3_test/lib/python3.8/site-packages/librosa/core/audio.py:162: UserWarning: PySoundFile failed. Trying audioread instead.
warnings.warn("PySoundFile failed. Trying audioread instead.")
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/files.py:105: UserWarning:
WARNING: Most functionality has not been tested with stereo sound. Many functions may fail or not work as expected. Apologies for the inconvenience!
warnings.warn(msg)
67% through logging audio file details
70% through logging audio file details
74% through logging audio file details
77% through logging audio file details
80% through logging audio file details
83% through logging audio file details
87% through logging audio file details
90% through logging audio file details
93% through logging audio file details
96% through logging audio file details
100% through logging audio file details
This returns our data in a dictionary, perfect for exploring via Pandas
import pandas as pd
all_data = pd.DataFrame(dataset_info_dict).T
all_data.head()
| audio | sr | num_channels | dur_sec | format_type | bitdepth | |
|---|---|---|---|---|---|---|
| ../../../audiodata2/dogbark_2channels.wav | ../../../audiodata2/dogbark_2channels.wav | 48000 | 2 | 0.389 | WAV | PCM_16 |
| ../../../audiodata2/python_traffic_pf.wav | ../../../audiodata2/python_traffic_pf.wav | 48000 | 1 | 1.86 | WAV | DOUBLE |
| ../../../audiodata2/259672__nooc__this-is-not-right.wav | ../../../audiodata2/259672__nooc__this-is-not-... | 44100 | 1 | 2.48454 | WAV | PCM_16 |
| ../../../audiodata2/259672__nooc__this-is-not-right.flac | ../../../audiodata2/259672__nooc__this-is-not-... | 44100 | 1 | 2.48454 | FLAC | PCM_16 |
| ../../../audiodata2/505803__skennison__new-recording.wav | ../../../audiodata2/505803__skennison__new-rec... | 48000 | 1 | 5.63067 | WAV | PCM_16 |
Let’s have a look at the audio files and how uniform they are:
print('formats: ', all_data.format_type.unique())
print('bitdepth (types): ', all_data.bitdepth.unique())
print('mean duration (sec): ', all_data.dur_sec.mean())
print('std dev duration (sec): ', all_data.dur_sec.std())
print('min sample rate: ', all_data.sr.min())
print('max sample rate: ', all_data.sr.max())
print('number of channels: ', all_data.num_channels.unique())
Out:
formats: ['WAV' 'FLAC' 'M4A' 'MP3' 'OGG' 'AIFF']
bitdepth (types): ['PCM_16' 'DOUBLE' 'FLOAT' 'unknown' 'PCM_24' 'VORBIS' 'PCM_U8']
mean duration (sec): 3.8668231521103054
std dev duration (sec): 3.394200829629172
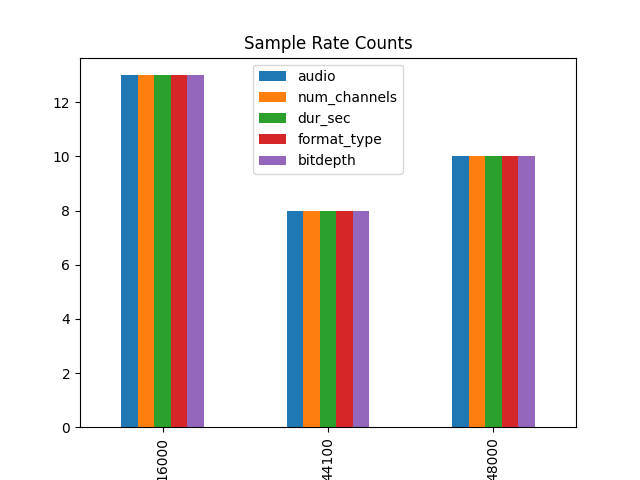
min sample rate: 16000
max sample rate: 48000
number of channels: [2 1]
For a visual example, let’s plot the count of various sample rates. (48000 Hz is high definition sound, 16000 Hz is wideband, and 8000 Hz is narrowband, similar to how speech sounds on the telephone.)
all_data.groupby('sr').count().plot(kind = 'bar', title = 'Sample Rate Counts')
Out:
<AxesSubplot:title={'center':'Sample Rate Counts'}, xlabel='sr'>
Reformat a Dataset¶
Let’s say we have a dataset that we want to make consistent. We can do that with soundpy
new_dataset_dir = sp.builtin.dataset_formatter(
dataset_path,
recursive = True, # we want all the audio, even in nested directories
format='WAV',
bitdepth = 16, # if set to None, a default bitdepth will be applied
sr = 16000, # wideband
mono = True, # ensure data all have 1 channel
dur_sec = 3, # audio will be limited to 3 seconds
zeropad = True, # audio shorter than 3 seconds will be zeropadded
new_dir = './example_dir/', # if None, a time-stamped directory will be created for you
overwrite = False # can set to True if you want to overwrite files
);
Out:
/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/soundpy/files.py:352: UserWarning: Some files did not match those acceptable by this program. (i.e. non-audio files) The number of files not included: 3300
warnings.warn(message)
File example_dir/audiodata2/dogbark_2channels.wav already exists.
3% through reformatting datasetFile example_dir/audiodata2/python_traffic_pf.wav already exists.
6% through reformatting datasetFile example_dir/audiodata2/259672__nooc__this-is-not-right.wav already exists.
9% through reformatting datasetFile example_dir/audiodata2/259672__nooc__this-is-not-right.wav already exists.
12% through reformatting datasetFile example_dir/audiodata2/505803__skennison__new-recording.wav already exists.
16% through reformatting datasetFile example_dir/audiodata2/male_noisy60snr_marvin.wav already exists.
19% through reformatting datasetFile example_dir/audiodata2/python_traffic_wiener.wav already exists.
22% through reformatting datasetFile example_dir/audiodata2/male_noisy30snr_marvin.wav already exists.
25% through reformatting datasetFile example_dir/audiodata2/female_noisy10snr_python.wav already exists.
29% through reformatting datasetFile example_dir/audiodata2/rain.wav already exists.
32% through reformatting datasetFile example_dir/audiodata2/python.wav already exists.
35% through reformatting datasetFile example_dir/audiodata2/python_traffic_bs.wav already exists.
38% through reformatting datasetFile example_dir/audiodata2/left.wav already exists.
41% through reformatting dataset/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/p3_test/lib/python3.8/site-packages/librosa/core/audio.py:162: UserWarning: PySoundFile failed. Trying audioread instead.
warnings.warn("PySoundFile failed. Trying audioread instead.")
File example_dir/audiodata2/505803__skennison__new-recording.wav already exists.
45% through reformatting datasetFile example_dir/audiodata2/240674__zajo__you-have-been-denied.wav already exists.
48% through reformatting datasetFile example_dir/audiodata2/male_noisy10snr_marvin.wav already exists.
51% through reformatting datasetFile example_dir/audiodata2/python_traffic.wav already exists.
54% through reformatting datasetFile example_dir/audiodata2/marvin.wav already exists.
58% through reformatting datasetFile example_dir/audiodata2/male_noisy20snr_marvin.wav already exists.
61% through reformatting datasetFile example_dir/audiodata2/female_noisy60snr_python.wav already exists.
64% through reformatting dataset/home/airos/Projects/github/a-n-rose/Python-Sound-Tool/p3_test/lib/python3.8/site-packages/librosa/core/audio.py:162: UserWarning: PySoundFile failed. Trying audioread instead.
warnings.warn("PySoundFile failed. Trying audioread instead.")
File example_dir/audiodata2/244287__kleinhirn2000__toast-glas-langsam.wav already exists.
67% through reformatting datasetFile example_dir/audiodata2/car_horn.wav already exists.
70% through reformatting datasetFile example_dir/audiodata2/wow.wav already exists.
74% through reformatting datasetFile example_dir/audiodata2/240674__zajo__you-have-been-denied.wav already exists.
77% through reformatting datasetFile example_dir/audiodata2/traffic.wav already exists.
80% through reformatting datasetFile example_dir/audiodata2/traffic.wav already exists.
83% through reformatting datasetFile example_dir/audiodata2/female_noisy30snr_python.wav already exists.
87% through reformatting datasetFile example_dir/audiodata2/female_noisy20snr_python.wav already exists.
90% through reformatting datasetFile example_dir/audiodata2/244287__kleinhirn2000__toast-glas-langsam.wav already exists.
93% through reformatting datasetFile example_dir/audiodata2/audio2channels.wav already exists.
96% through reformatting datasetFile example_dir/audiodata2/187915__vasotelvi__transfer-is-complete.wav already exists.
100% through reformatting dataset
Let’s see what the audio data looks like now:
dataset_formatted_dict = sp.builtin.dataset_logger(new_dataset_dir, recursive=True);
formatted_data = pd.DataFrame(dataset_formatted_dict).T
Out:
3% through logging audio file details
7% through logging audio file details
11% through logging audio file details
15% through logging audio file details
19% through logging audio file details
23% through logging audio file details
26% through logging audio file details
30% through logging audio file details
34% through logging audio file details
38% through logging audio file details
42% through logging audio file details
46% through logging audio file details
50% through logging audio file details
53% through logging audio file details
57% through logging audio file details
61% through logging audio file details
65% through logging audio file details
69% through logging audio file details
73% through logging audio file details
76% through logging audio file details
80% through logging audio file details
84% through logging audio file details
88% through logging audio file details
92% through logging audio file details
96% through logging audio file details
100% through logging audio file details
formatted_data.head()
| audio | sr | num_channels | dur_sec | format_type | bitdepth | |
|---|---|---|---|---|---|---|
| example_dir/audiodata2/dogbark_2channels.wav | example_dir/audiodata2/dogbark_2channels.wav | 8000 | 1 | 3 | WAV | PCM_16 |
| example_dir/audiodata2/python_traffic_pf.wav | example_dir/audiodata2/python_traffic_pf.wav | 8000 | 1 | 3 | WAV | PCM_16 |
| example_dir/audiodata2/259672__nooc__this-is-not-right.wav | example_dir/audiodata2/259672__nooc__this-is-n... | 8000 | 1 | 3 | WAV | PCM_16 |
| example_dir/audiodata2/505803__skennison__new-recording.wav | example_dir/audiodata2/505803__skennison__new-... | 8000 | 1 | 3 | WAV | PCM_16 |
| example_dir/audiodata2/male_noisy60snr_marvin.wav | example_dir/audiodata2/male_noisy60snr_marvin.wav | 8000 | 1 | 3 | WAV | PCM_16 |
print('audio formats: ', formatted_data.format_type.unique())
print('bitdepth (types): ', formatted_data.bitdepth.unique())
print('mean duration (sec): ', formatted_data.dur_sec.mean())
print('std dev duration (sec): ', formatted_data.dur_sec.std())
print('min sample rate: ', formatted_data.sr.min())
print('max sample rate: ', formatted_data.sr.max())
print('number of channels: ', formatted_data.num_channels.unique())
Out:
audio formats: ['WAV']
bitdepth (types): ['PCM_16']
mean duration (sec): 3.0
std dev duration (sec): 0.0
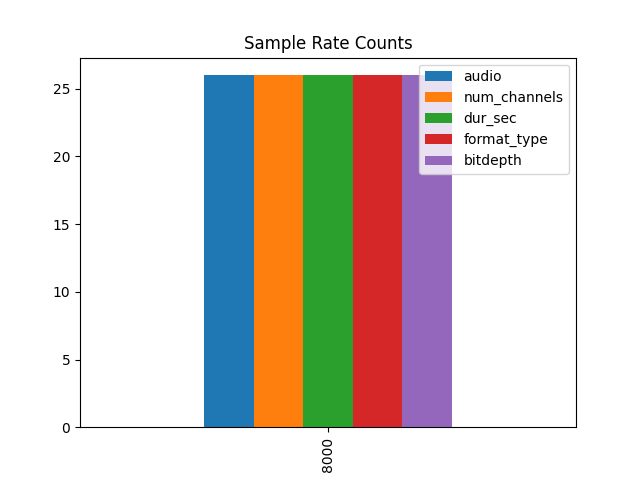
min sample rate: 8000
max sample rate: 8000
number of channels: [1]
Now all the audio data is sampled at the same rate: 8000 Hz
formatted_data.groupby('sr').count().plot(kind = 'bar', title = 'Sample Rate Counts')
Out:
<AxesSubplot:title={'center':'Sample Rate Counts'}, xlabel='sr'>
There we go!
You can reformat only parts of the audio files, e.g. format or bitdepth.
If you leave parameters in sp.builtin.dataset_formatter as None, the original
settings of the audio file will be maintained (except for bitdepth.
A default bitdepth will be applied according to the format of the file); see soundfile.default_subtype.
Total running time of the script: ( 0 minutes 3.239 seconds)